语音笔记自动化:我是怎么把每天的碎碎念变成可发布内容的

我有一个用了好几年的习惯:随时录音。
走路想到什么,录。开车有个念头,录。刚开完会脑子还热着,录。我用的是一支 DJI Mic 3,小小一个挂在脖子上,按一下就开始录,再按一下停,文件自动存到录音笔的内存里。

问题是录完以后怎么办。
把录音导出来、用工具转成文字、再手动整理成结构化的笔记、再决定哪些内容可以发布、发布前再润色一遍... 每一步都不难,但加在一起每天要花掉我一到两个小时。而且这件事没有截止日期,没有外部压力,所以它很容易就被推到"等我有空的时候"那个抽屉里。
结果就是:录了很多音,整理了很少,发布了更少。
我真正想要的是什么
我给自己设了一个目标:把整个流程压缩到"一条命令"。
录音笔 SD 卡里的文件拷进来,跑一个脚本,然后我就能在 Obsidian 里看到当天整理好的笔记。如果有些内容值得发布,打个 #Share 标签,再跑一个命令,三个平台(推特、LinkedIn、YouTube)各自准备好的内容就全存到内容库里。
这不是说我想让 AI 替我写东西。我想要的是:我的想法,我的声音,用我的语气写出来,但不需要我坐在那里一个字一个字整理。整个过程我可以全程不参与,但每个环节都有我的影子。
这是一个细节上的区别,但对我来说非常重要。
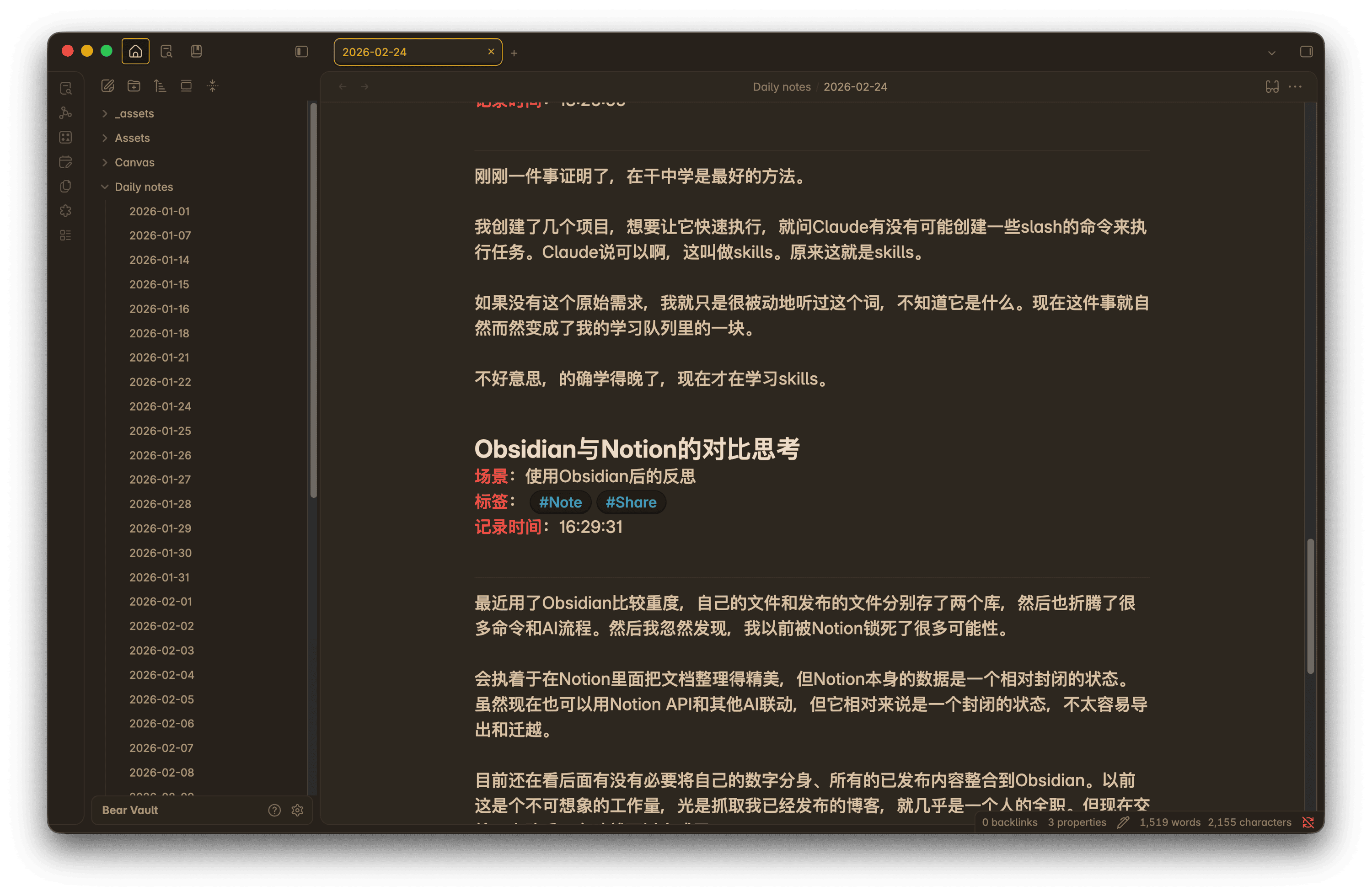
这就是最终成果:AI自动整理的笔记,按天、分类,自动加上标签和场景。
动手之前先想清楚架构
我不会编程,但我会用 Claude Code 做 Vibe Coding。对我来说,这个过程有点像跟一个超级靠谱的工程师结对——我说想法,它写代码,我测试,出了问题一起 debug,然后继续迭代。
整个流程我拆成三个阶段:
第一阶段:录音变文字。 录音笔里出来的 .wav 文件,用 Whisper 模型转成文本。我优先用 Buzz(一个 macOS 上的 Whisper GUI),失败了自动切到 Python 的 whisper 库。
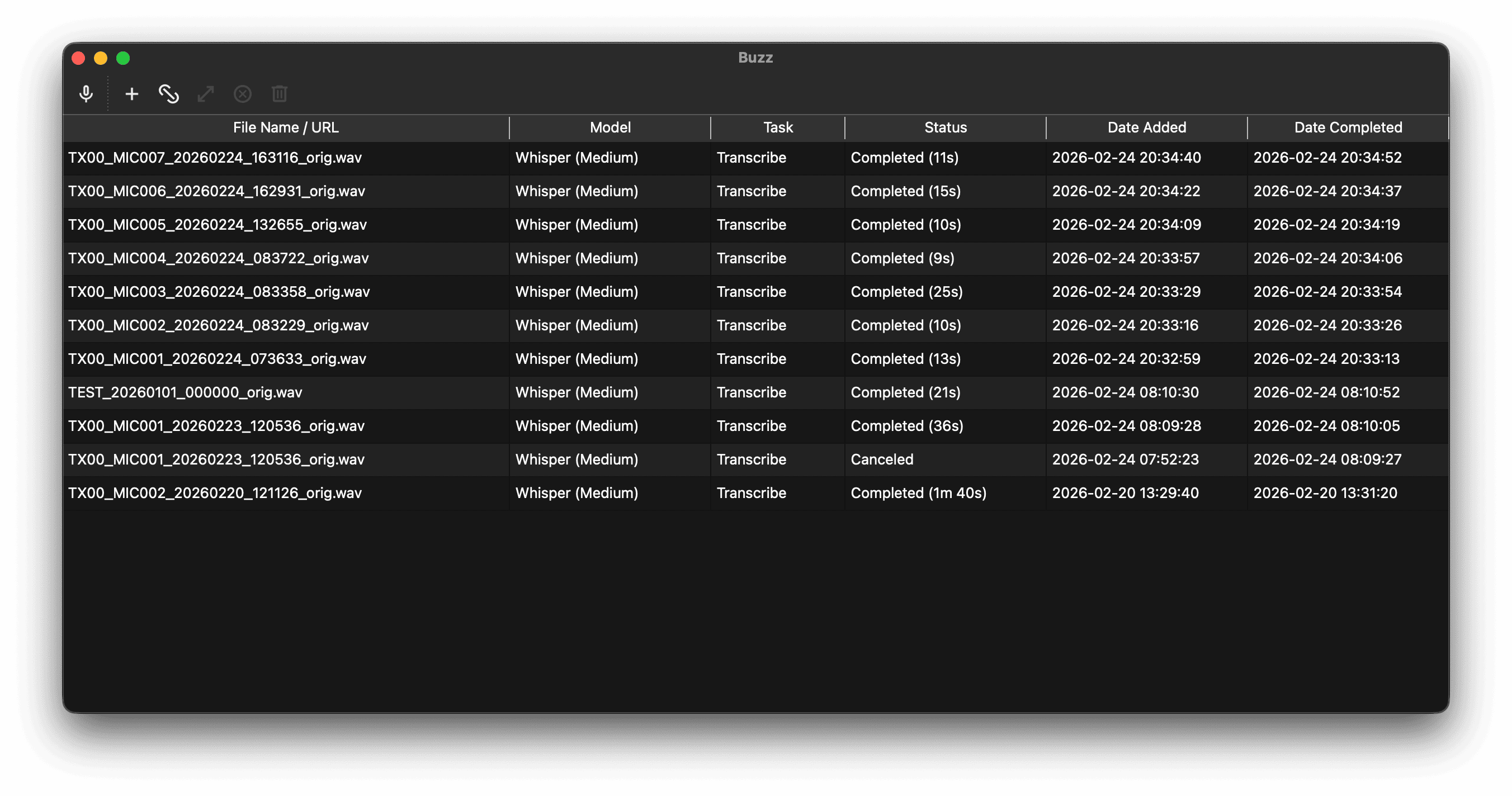
第二阶段:文字变笔记。 把一天的转写文本打包发给 Claude API,让它帮我整理成结构化的 Markdown 笔记。每条笔记有标题、场景标注、时间戳,内容一字不删,只修错别字和断句。
第三阶段:笔记变帖子。 我在笔记里打 #Share 标签的条目,会被提取出来,然后再调用一次 Claude,同时生成三个版本:推特中文长文、LinkedIn 英文、YouTube Shorts 标题加 hashtag。每条帖子单独存成一个 Markdown 文件,进我的内容库。
实际搭建的过程
说起来三步,做起来当然不是这么顺滑的。
最开始的 bug 很典型:Buzz 的命令行接口在新版本里把子命令藏起来了。我的代码直接调 Buzz --task transcribe ...,结果它每次都悄悄打开 GUI 等待用户操作,两分钟超时,然后 fallback 到 whisper。程序没报错,但其实从来没有真正用过 Buzz。
找到原因的时候有点好笑。正确的调用方式是 Buzz add --task transcribe ...,差一个 add,完全两种行为。而且 Buzz 输出的文件名还带着时间戳后缀,跟代码里预期的不一样,又要加一步重命名。这种 "程序跑通但结果不对" 的情况,是 Vibe Coding 里最难调的——因为你的第一反应是"它成功了",而不是"这里有问题"。
比较有意思的是 token 截断的问题。生成社交帖子时,我给 Claude 的 max tokens 按输入长度的 1.2 倍估算。听起来有余量,但问题是:输入是一段语音笔记,输出要生成三个平台的内容,实际输出量是输入的三四倍。7 条笔记送进去,只有 6 条出来,最后一条被截断了。改成 4 倍之后,全部完整。
还有一个关于架构判断的决策,我选择了"一次 API 调用生成所有平台内容",而不是分三次。这样更快,而且 Claude 能在同一个上下文里保持语气的一致性。代价是 prompt 要写得更清楚,每个平台的要求要讲明白。
现在的运行效果
目前这套流程已经稳定跑了几周。
每天的录音,从录音笔拷出来,跑一条命令,几分钟之内就能在 Obsidian 里看到当天的笔记。12 条语音,8 个主题,时间戳、场景标注都在,全量保留,没有任何删减。
社交帖子的部分,我在笔记里标注好 #Share,跑一条命令,每条帖子就有推特、LinkedIn 和 YouTube Shorts 三个版本,按月份存到 Bear Content Vault 里,等我发布的时候直接拿来用或者微调。
最让我觉得值得的,是我现在在做这件事的过程本身。我不需要在发布的时候再坐下来想"这条内容怎么改成英文",也不需要在录完音之后马上找时间整理,流程已经在那里了,我的工作是往里放原材料,它自动处理。
几个我认为重要的设计判断
零删减原则。 精修只修错别字和断句,不压缩、不总结、不删内容。这条原则很重要,因为我记录语音的目的是把脑子里的东西完整地留下来,而不是只留下重点。
幂等设计。 所有步骤重复运行都是安全的,已处理的文件会被跳过。这让我可以随时中断,随时继续,不用担心重复处理或数据丢失。
分层输出。 同一批内容,一次处理完,同时输出到三个平台。这不只是效率问题,更是风格一致性问题。在同一个 context 里生成的内容,表达方式更统一,比分开处理更自然。
还在想的事情
这套流程里有个地方我还没解决:会议和通话。
我有时候会和客户开会,和合作者通话,这些录音里有很多有价值的东西。但它的处理方式跟个人语音笔记不太一样,它需要的是"结构化摘要",包括议题、决策、行动项,而不是全量保留。这是下一个要做的版本。

还有一件更有意思的事:当我把播客的制作也自动化了之后,我发现自己一周能更新三期,而原来只能一期。内容量上去了,但"我在每期里的存在感"反而没有消失,因为那些材料、那些判断、那些措辞,还是我的。
这就是我认为好的自动化应该长的样子:不是替代你,而是让你的东西跑得更远。
工具链
- 硬件:DJI Mic 3 录音笔
- 转写:Buzz(macOS)/ OpenAI Whisper(fallback)
- 精修 & 生成:Claude API(claude-sonnet-4-5)
- 笔记管理:Obsidian
- 内容库:Bear Content Vault(iCloud 同步)
- 代码协作:Claude Code(Vibe Coding)
项目开源在 GitHub:voice-daily-note